|
Mesh of the Aircraft scene |
Aircraft scene and the corresponding groups (30K original polygons and 480 groups) |
In that deliverable, we had identified an important requirement for hierarchical radiosity with clustering: monotonicity of solution quality. In practice this has two forms: when the user lowers the error threshold, the quality of the solution should improve, and when we plot a graph of time vs. error, the longer the solution, the better the quality should be.
To the naive user, these two requirements are obvious. What comes as a surprise is that using the existing clustering algorithms, neither of the above requirements is necessarily satisfied.
In this document and in the publication [Has99], we demonstrate that clustering algorithms do not always satisfy these criteria by extending and continuing our experimental study.
In the sections that follow we outline these conclusions in some detail. We have shown that clustering works well for scenes containing a significant number of large objects (walls, floors, large desk surfaces), and an organised set of other objects (desks etc.). However for models containing large numbers of small disorganised objects (resulting from tesselations for example) clustering algorithms do not perform very well.
To address this shortcoming to some extent, we have introduced a novel clustering algorithm which attempts to group small disorganised objects. In combination with our new mixed algorithm, we show that this approach improves the solution for the difficult cases which were not well treated by previous methods.
The rest of this document is structured as follows: we present the novel object-grouping algorithm; we then present the experimental study on the monotonicity of error, including statistics for the object-group approach; we conclude. Many parts of this document are based on the Eurographics 99 publication
The goal of our new algorithm is to improve the performance of clustering algorithms for scenes containing many small unorganised polygons. Examples of these scenes include objects resulting from tesselation, terrains etc. We follow the intuitive direction of attempting to group objects which "belong" together either geometrically or otherwise.
The new algorithm is a two-pass approach. In particular we first group objects into "intuitive" sets in a completely automatic manner. We then cluster these groups so that an hierarchy is built in the interior of each group. Finally the resulting clusters are added into an overall hierarchy built using our OKDT-P two-pass clustering algorithm, which constructs an octree top-down and then collects the cluster bottom-up to produce a tight bounding volume hierarchy (see [Has99] for details).
The new approach succeeds in creating "natural" clusters. In scenes resulting from tesselation (such as the aircraft interior shown below), the grouping approach manages to create logical groups, such as the polygons comprising the different parts of each seat etc. This is shown by the colour-coded version of these scenes, where objects belonging to each group have the same colour.
|
Mesh of the Aircraft scene |
Aircraft scene and the corresponding groups (30K original polygons and 480 groups) |
In this section we describe the continuation of the experimental study performed in our first deliverable for this task (2.1-1). The goal of this study is to evaluate how useable the clustering algorithms are, in the sense of error monotonicity as described in the introduction.
To do this we required a way to evaluate the quality of the solutions, and an experimental procedure to determine the behaviour of each algorithm tested. The goal is to study quality vs time, i.e., the error monotonicity of the clustering algorithms under consideration.
For more details on tests, see [Has99].
We ran all algorithms on a Silicon Graphics computer (MIPS R10000 at 250 MHZ) with 4GB of memory. The four scenes tested are as in Deliv. 2.1-1: AIRCRAFT, CAR, OFFICE and VRLAB.
| Time | Error | |||||||||
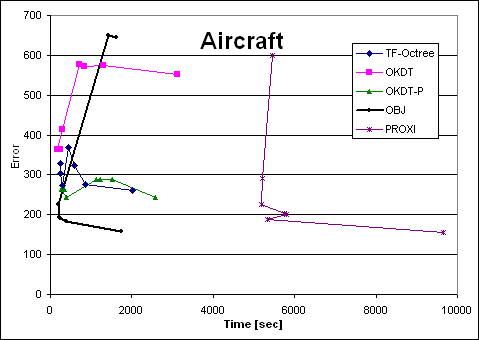
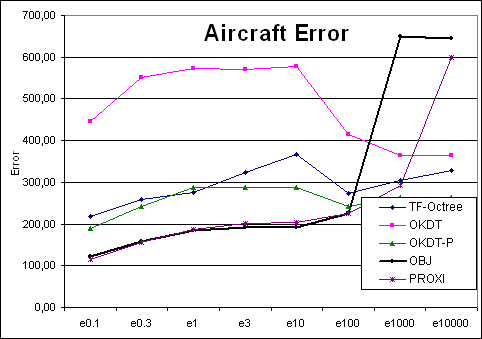
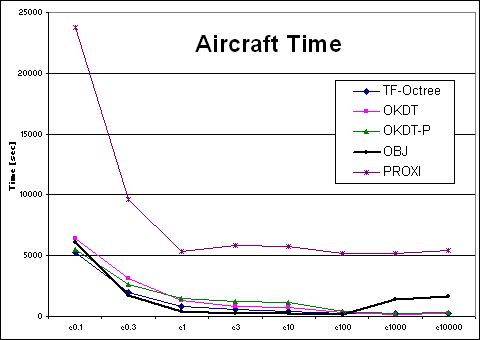
| Aircraft | TF-Octree | OKDT | OKDT-P | OBJ | PROXI | TF-Octree | OKDT | OKDT-P | OBJ | PROXI |
| e0.3 | 2013 | 3120 | 2592 | 1748 | 9644 | 259.8406 | 552.1662 | 242.5172 | 158.1884 | 154.671 |
| e1 | 854 | 1290 | 1521 | 385 | 5328 | 275.9148 | 573.8866 | 288.5766 | 184.0492 | 187.5412 |
| e3 | 584 | 826 | 1220 | 245 | 5806 | 323.306 | 570.9244 | 288.8684 | 190.9694 | 200.8728 |
| e10 | 445 | 703 | 1133 | 212 | 5757 | 367.6 | 577.988 | 288.6658 | 192.8452 | 202.7964 |
| e100 | 287 | 299 | 381 | 199 | 5185 | 272.5334 | 413.9436 | 242.527 | 225.363 | 224.583 |
| e1000 | 246 | 166 | 273 | 1425 | 5220 | 303.8444 | 363.3248 | 262.7726 | 648.7452 | 291.4572 |
| e10000 | 250 | 240 | 342 | 1622 | 5447 | 327.4508 | 363.3248 | 262.7726 | 643.8776 | 598.4482 |
| Time | Error | |||||||||
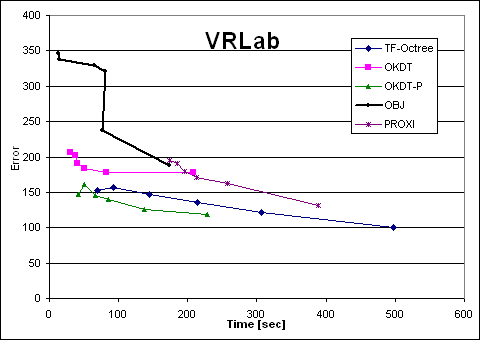
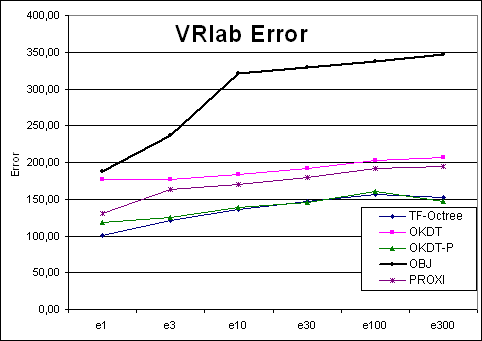
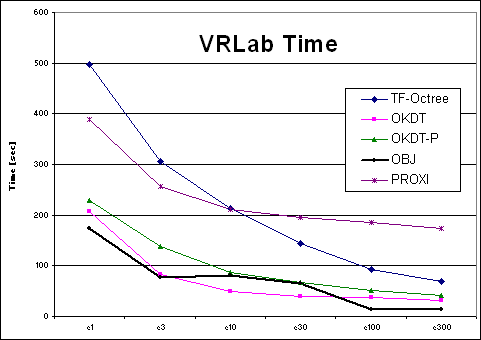
| VRLab | TF-Octree | OKDT | OKDT-P | OBJ | PROXI | TF-Octree | OKDT | OKDT-P | OBJ | PROXI |
| e1 | 497 | 208 | 229 | 173 | 389 | 100.44446 | 177.432 | 118.27206 | 188.1908 | 131.26766 |
| e3 | 306 | 83 | 138 | 76 | 257 | 121.635 | 177.4712 | 125.1071 | 237.3672 | 162.9742 |
| e10 | 214 | 50 | 86 | 81 | 212 | 136.2262 | 184.0652 | 139.45572 | 320.4326 | 170.3866 |
| e30 | 144 | 40 | 67 | 65 | 195 | 146.5932 | 191.2458 | 146.25542 | 328.961 | 179.74 |
| e100 | 93 | 37 | 51 | 14 | 185 | 156.481 | 202.5076 | 160.91228 | 337.5742 | 191.5048 |
| e300 | 69 | 31 | 42 | 13 | 174 | 152.8926 | 207.0122 | 147.3944 | 346.7308 | 194.4094 |
| Time | Error | |||||||||
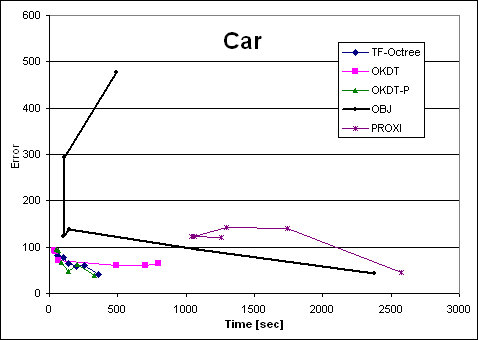
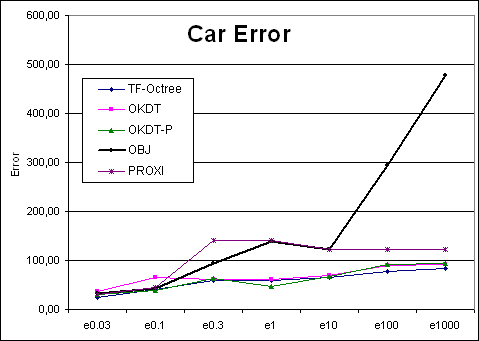
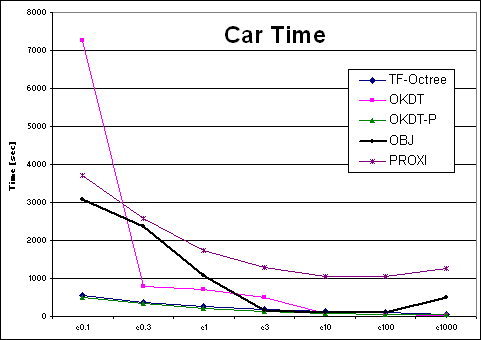
| Car | TF-Octree | OKDT | OKDT-P | OBJ | PROXI | TF-Octree | OKDT | OKDT-P | OBJ | PROXI |
| e0.3 | 360 | 796 | 331 | 2375.6 | 2576 | 39.95664 | 65.04398 | 38.5255 | 42.70744 | 44.46318 |
| e1 | 253 | 702 | 203 | 1082.7 | 1742 | 59.42226 | 60.72704 | 63.50708 | 93.97838 | 139.84646 |
| e3 | 194 | 487 | 141 | 148.1 | 1293 | 59.23804 | 60.63924 | 46.49458 | 138.56236 | 141.41034 |
| e10 | 139 | 69 | 89 | 103.1 | 1064 | 64.62112 | 70.2345 | 67.7094 | 123.27486 | 122.9752 |
| e100 | 103 | 43 | 64 | 108.1 | 1040 | 77.82686 | 90.53802 | 92.7872 | 293.7524 | 122.16888 |
| e1000 | 59 | 37 | 49 | 492.9 | 1259 | 82.74796 | 91.889 | 94.5907 | 476.8818 | 121.923 |
| Time | Error | |||||||||
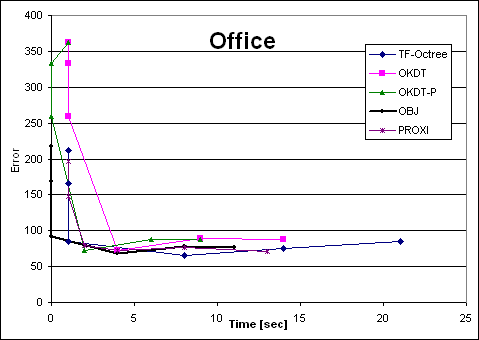
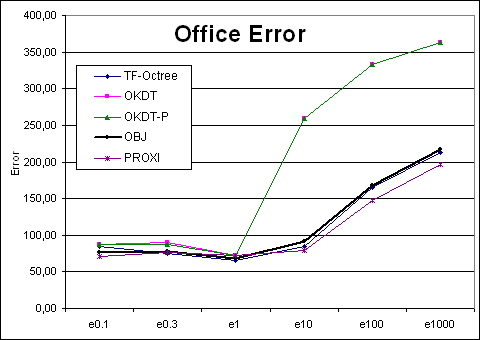
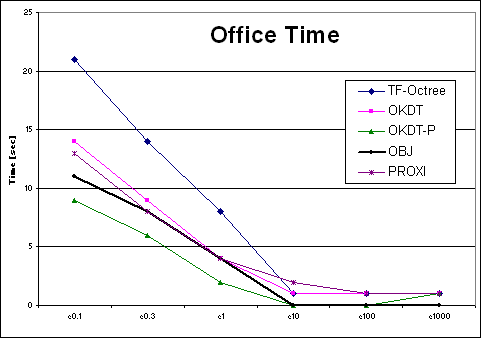
| Office | TF-Octree | OKDT | OKDT-P | OBJ | PROXI | TF-Octree | OKDT | OKDT-P | OBJ | PROXI |
| e0.1 | 21 | 14 | 9 | 11 | 13 | 84.448025 | 87.916 | 87.20935 | 76.065 | 71.100125 |
| e0.3 | 14 | 9 | 6 | 8 | 8 | 75.72165 | 89.64355 | 87.2469 | 77.6143 | 76.93375 |
| e1 | 8 | 4 | 2 | 4 | 4 | 64.916875 | 72.0457 | 72.63665 | 68.91165 | 72.32025 |
| e10 | 1 | 1 | 0 | 0 | 2 | 84.7812 | 259.65425 | 259.74375 | 91.8799 | 79.029525 |
| e100 | 1 | 1 | 0 | 0 | 1 | 165.86725 | 332.76775 | 332.76825 | 168.3995 | 147.27575 |
| e1000 | 1 | 1 | 1 | 0 | 1 | 212.5075 | 362.69475 | 362.69625 | 217.404 | 195.967 |
Office Time curves |
Car Time curves |
VRLab Time curves |
Aircraft Time curves |
Office Error curves |
|
VRLab Error curves |
Aircraft Error curves |
Time/Error curves |
Car Time/Error curves |
Time/Error curves |
Time/Error curves |
In this section, we present a number of observations drawn from the tests result presented. We begin with an analysis of the quality aspects of the simulations, looking at the evolution of our error measure with the user-defined error tolerance. We then consider in more detail the capacity of different clustering techniques to assist visibility calculations, with a particular emphasis on computational efficiency.
Recall from the introduction that a major demand on the clustering mechanism (together with the chosen refinement strategy) is that the evolution of computation time and solution quality should be regular and monotonic as the user changes the error tolerance (Figure above). Ideally, this would result in a very regular and monotonic time/error curve. Such curves are presented in Figure above for the four test scenes.
Looking at the four Time-error curves, we see two very different types of behaviours: for the OFFICE and VRLAB scenes, all curves are regular and fairly monotonic, whereas for AIRCRAFT and CAR the variation of error is more erratic. Indeed, looking at a plot of error as a function of the user-supplied error tolerance, we find that the error in the solution does not always decrease as we reduce the tolerance.
Why can the error increase when we decrease our tolerance? This unfriendly behaviour occurs when links refined as a result of the error tolerance change produce a less accurate representation of radiosity exchanges. This is largely a question of refinement criteria, but is also influenced by the clustering strategy, as well as the distribution of objects in the scene. We observe that our scenes can be classified into two types: AIRCRAFT and CAR consist of many small polygons, because of a previous tessellation of the objects. VRLAB and OFFICE, on the other hand, contain objects of varying size, from large walls to small furniture components. Based on our experience and the results of the above experiments, we observe that clustering algorithms have more difficulty with the first type of scene ("polygon soup"). This is especially true of AIRCRAFT because 3D space is very densely populated, resulting in many interactions between clusters which are not separated by a significant distance. These interactions also present a particular challenge to the refinement criterion.
It is instructive to observe the behaviour of the new OBJ algorithm on the test scenes. Recall that the goal of this algorithm is to improve the behaviour of previous clustering approaches for the "polygon soup" type scenes, i.e., the AIRCRAFT and CAR. If we exclude the cases of very high tolerance values (epsilon threshold > 200) we see that the OBJ algorithm is as smooth as the PROXI approach, but much faster. For the CAR scene, the results are encouraging, although not quite as good. This is due to the particular nature of the CAR model, which contains many small objects which cannot be grouped by the current form of the OBJ algorithm (the components of the control panel are modelled in detail for example). Better clustering after group creation would solve these issues.
Drawing concrete conclusions from experimental tests such as those performed here is always a delicate task. Nonetheless, there are certain elements which we believe are clear enough to be singled out:
Clustering works well in many cases: in particular, for scenes containing objects of different sizes and a sufficient number of large initial surfaces (walls, floors etc.), all the clustering algorithms tested appear to perform well. The Time-error graphs are smooth and monotonic for these cases, presenting the user with an intuitive time-quality tradeoff.
Of the previously existing clustering algorithms tested, the hierarchical bounding volumes (PROXI) approach seems to have the most predictable behaviour in almost all cases. In particular, the Time-error curve is almost always monotonic and smooth. In addition, due to the nature of construction, it fits objects more tightly, which is a desirable property for clustering. However the overhead for PROXI is significant if not prohibitive in most cases: a much longer construction time (compared to all others tested), longer solution times, and in some cases a higher absolute error for very approximate simulations, often with objectionable visual artifacts.
For scenes containing many small objects ("polygon soup"), previous clustering algorithms are less well-behaved. In particular, more time spent computing a solution does not always result in higher quality. This is even more troublesome since the scenes in question are typical of industrial "real-world" models, which are often the result of a fine tessellation of some unspecified and unrecoverable modeling format.
The new object-grouping algorithm presented improves the results for these scenes. In particular, it performs at least as well as the PROXI approach, but is much faster. For the AIRCRAFT scene, where the seats of the plane correspond well to the specifications of groups of objects as required by the grouping algorithm. In addition the construction time for OBJ is negligible compared to the PROXI approach.
The work of this task has resulted in significant advances in the comprehension of the difficulties related to clustering for hierarchical radiosity. We have tested different algorithms, and we have seen that exisiting algorithms work quite well for organised scenes, while a novel algorithms was introduced to improve performance for the case of large sets of small disorganised polygons.
Clearly, there is future work to be done in this domain, since clustering remain a very hard problem.
The error metric adopted for our tests is one of many possibilities. It is evident that different applications have different notions of error (for example in lighting design where an exact measure of energy prevails over image quality), and these different requirements will lead to different choices for clustering. These issues must be further investigated.
The initial, first-order, classification of scene "type" with respect to their behavior in the context of a clustering algorithm is an interesting avenue of research. Ideally, extensive experimentation would allow us to determine which algorithm is suitable for a given scene. This is however a very ambitious task, so even initial results would be worthy of further research.
In terms of hierarchical radiosity with clustering, building the cluster hierarchy is but one step. The refinement algorithm used is a central component which can be adapted to deal with many of the problems which remain. For example, we have seen that overlapping clusters remain in almost all of the clustering approaches which perform well. Depending on the effect of such a configuration in a given radiosity solution, the refiner can be adapted to overcome the consequent imprecision, simply by forcing the subdivision of links between such clusters. Other more involved refinement strategies must be also be developed; this is ongoing work of work package 3.2.2
To conclude, we believe that our analysis has shown the utility of clustering for many cases, identified some weaknesses of current algorithms and identified certain important properties of each algorithm with respect to their suitability for different tasks.
The OBJ algorithm can be improved in several ways. In particular, once the object groups have been constructed, we currently apply a simplistic clustering algorithm to group the objects themselves, which results in the problems seen in the results for example of the CAR scene. A more appropriate PROXI step for example would alleviate this problem. In the same spirit, the actual clustering in the interior of objects can be improved.
An alternative to this approach is the use of multiresolution models for complex objects such as car seats etc. Many problems still remain for this type of approach; some solutions are being developed in the context of task 2.3.